

Publications are equivalent to prestiges for
Don’t be afraid to skip getting all milestones to work on the next or a better theory.
Guide written by LE★Baldy & Snaeky. Contributions from the Amazing Community.
This guide is currently undergoing change. Keep in mind, strategies may change.
Feel free to use the glossary or Eylanding's simplified T1-4 guide as needed.
Publications are equivalent to prestiges for
Don’t be afraid to skip getting all milestones to work on the next or a better theory.
Remember to follow our routing advice from Introduction to Graduation.
| 5k | → | 5.2k | → | 5.6k | → | 5.8k | → | 6k |
| 6k | → | 7k | → | 8k | ||||
| 8k | → | 8.4k | → | 8.6k | → | 8.8k | → | 9k |
In mathematics, a recurrence relation is an equation that relies on an initial term and a previous term to change. We start with the current tick’s term,
This theory also has its adjusted tickspeed calculated by
The publication multiplier has no optimal fit, as it fluctuates a lot, but here is known: 4-6 to start; 3-4 between
The active strat follows but only works when you have all milestones past
Note: If you are not doing the active strat, then simply turn off
The video below is only good for early
| 0/0/1 | → | 0/0/1/1 | → | 0/1/1/1 |
| 3/1/1/1 |
| Or | ||||||
| 3 | → | 4 | → | 2 | → | 1x3 |
This second theory is focusing on derivatives. Derivatives in mathematics are the rate of change of the function they are the derivative of. For the case of
In simpler terms, it works similar to how
The optimal multiplier is pretty high and is not known before
For both strategies the milestones are listed in the order X>Y, where X and Y are the milestones as numerically ordered top to bottom in-game, are to be maxed in order from left to right.
For the idle strategy, you want to prioritize buying milestone levels of 1>2. If you have more than 4 milestones, you will prioritize milestone 1>2>3>4. You will want to publish at about 10-100 multiplier before
The goal of the active strategy is to grow
1-3 Milestones
3>4 (10s) → 1 (40s) → 3>4 (10s) → 2 (40s) →
repeat → coast and publish
4+ Milestones
3>4>1>2 (10s) → 1>2>3>4 (40s) →
3>4>1>2 (10s) → 2>1>3>4 (40s) →
repeat → coast and publish
Past
When you get to Theory 3 at ee7k, move on to pushing Theory 3 when active and running T2 overnight. The above is simply an option if you rather not work on T3 now.
| 2/0/0/0 | → | 2/2/0/0 | → | 2/2/3/0 |
| 2/2/3/3 |
| Or | ||||||
| 1 x2 | → | 2 x2 | → | 3 x3 | → | 4 x3 |
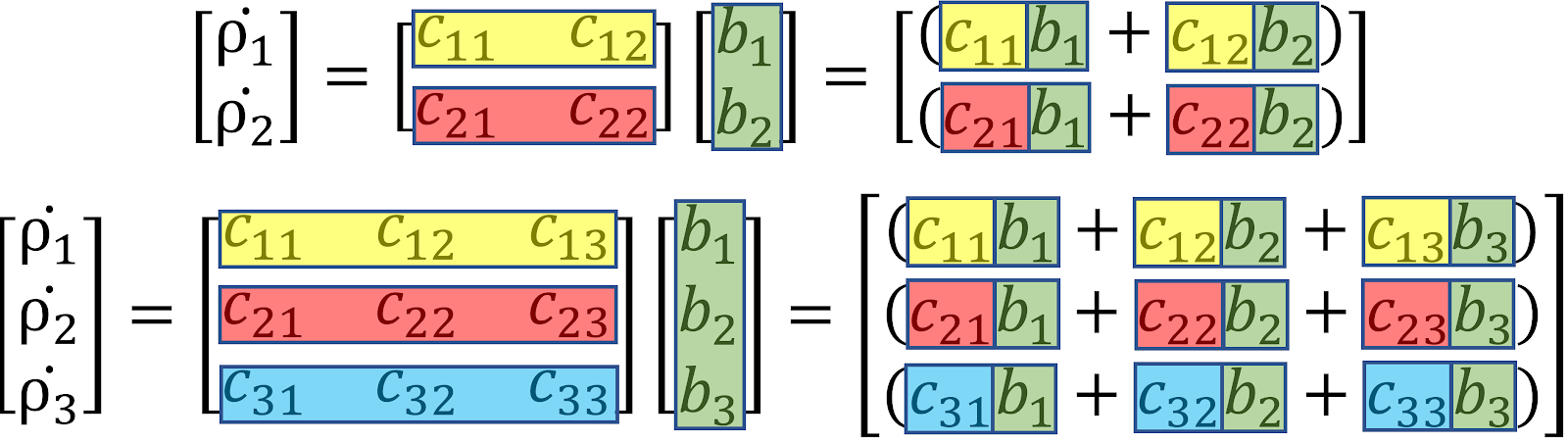
The basis of this theory and understanding how it works is based on
matrix multiplication. The following color-coding helps displays
how matrix multiplication works:
This gives the basis for why certain upgrades are more powerful than others. The exponents on
The optimal publication multiplier is about 2-3 without cruising and 3-4 with cruising. If you decide to play actively, there is a form of exponent swapping strat to be aware of. This is a difficult strategy because it requires you to notice when a certain threshold happens. It happens when the following occurs:
When this happens swap your exponents from
If you decide to buy manually, the focus areas are buying
At the end of any publication, around a 2-3 multiplier, you should turn off
| 0/2/0 | → | 0/2/2 | → | 1/2/2 |
| 1/2/2/2 |
| Or | ||||||
| 2 x2 | → | 3 x2 | → | 1 | → | 4 x2 |
Theory 4 is based on Polynomials, which contain terms of the form
The first line states that the rate of change of
The second line is more unique. It says that
For the more mathematically observant reader, we may integrate the
Approximate variable strengths on
| Brief Description | |
|---|---|
| ~7% increase on the |
|
| Doubles the |
|
| Doubles the |
|
| Doubles the |
|
| Doubles the |
|
| Doubles the |
|
| ~7% increase on |
|
| Doubles the instantaneous value of |
The strengths of each variable are as follows:
Early game (before 14k f(t)):
From 14k f(t) to mid-late game (about e350+ T4):
From e350+ T4 to end game:
T4 is quite idle friendly compared to T3 and T1. Here are some simple idle strategies for T4:
Start to e25:
Autobuy
e25 to e175:
Get the ‘Add the term’ milestones. Prioritize these ones first until maximum. Now autobuy
When
e175 to endgame:
Simply autobuy
There’s no strategic difference between semi-idle and idle for this theory. The main difference is with semi-idle, we would publish more often since we check the game more often. We wouldn’t overshoot the optimal multiplier as much.
T4 active is more involved. However it is not as demanding as T3 or T1 active.
Start to e75:
Autobuy
e75 to e175 OR 14k f(t):
Now here is where we can apply some more advanced strategies. Consider that the
If done right, this strategy is significantly faster than the idle strategies above. The logic with this strategy is that the
e175 OR 14k f(t) to ~e300 T4
We will do the exact same strategy as in the #start to
~e300 to endgame
At this point the
| 3/0/0 | → | 3/0/3 | → | 3/1/3 |
| Or | ||||
| 1 x3 | → | 3 x3 | → | 2 |
Before you reach 9k, these are the recommended values for each theory. You may not hit the values and have a different distribution, but work on getting these theories up to these values later. This list is in order of priority.
| Approximate |
|
|---|---|
| T2 | LATEXDOLLARe240-e300\ \tau$ |
| T1 | LATEXDOLLARe205-e215\ \tau$ |
| T3 | LATEXDOLLARe150\ \tau$ |
| T4 | LATEXDOLLARe150\ \tau$ |
{kind=link}